We warmly welcome the Visitor at the entrance gate of the portal introducing the climate modelling activities of the Hungarian Meteorological Service (OMSZ).
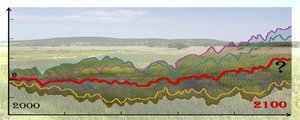
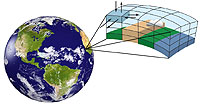
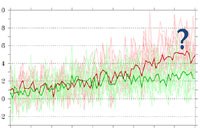
The Earth system change is a hot research issue recently, getting more and more attention in the public media as well as in our everyday life. The idea to initiate climate dynamics research in our institute (besides the traditional statistical climatology) had arisen in 2003, as modelling provides the only tool to explore the potential response of the climate system to a hypothetic anthropogenic forcing. The research background was ensured by the strong numerical weather prediction team and the high-capacity computer system developed in the preceding decade. The work started with the adaptation of several regional climate models (RCMs) in 2004. With the establishment of climate modelling fundaments, OMSZ could join to the European research network and participate in international co-operations investigating the climate change effects. The National Adaptation Geo-information System built in 2013 provides a harmonized basis for the adaptation studies using our RCM results as inputs for the quantitative climate impact assessments. Thanks to the efforts of the Regional Climate Modelling Group of OMSZ, the users have become acquainted with the probabilistic climate information and the decision making based on them.
Via our webpage, we invite the Visitor on the journey we have attended in the last more than 10 years. An overview is given on the Earth system, the influencing anthropogenic activity and the scientific means of future climate projections. Climate modelling basics are shown together with our most important RCM results, putting special emphasis on the expected changes in Hungary. We do our best to resolve the common misbelief that forecasts can be either entirely good or totally wrong, by explaining the more sophisticated probabilistic ensemble approach and the right interpretation of model results.
We wish You a pleasant time on our webpage!
| September 2017 |
| Regional Climate Modelling Group klimadinamika@met.hu |
| Modelling background |
Model experiments |
Climate indices | Uncertainties |
 |
 |
 |
 |
| Application | Urban climate modeling |
Projects | Outreach |
 |
 |
 |
 |